What We Do
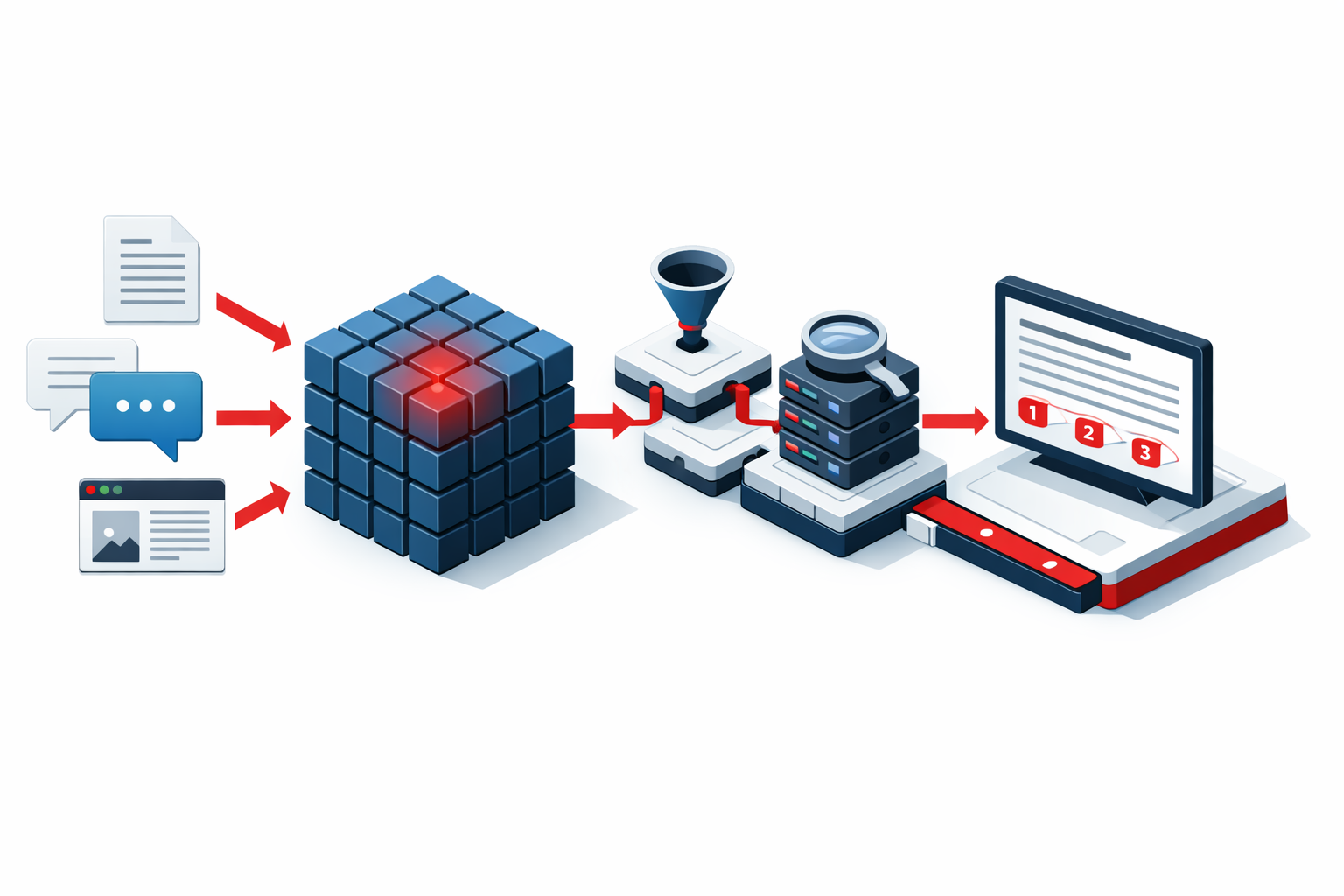
Your organization already has the answers. They are buried in SharePoint folders, Confluence pages, Google Drive documents, Slack archives, recorded meetings, and email threads. Your team spends hours every week searching for information that already exists somewhere in your systems. Retrieval-Augmented Generation changes that. A RAG system ingests your documents, indexes them semantically, and gives your team a single interface to ask questions in plain language.
The answer comes back in seconds with citations pointing to the exact source document. Not a list of search results. Not a hallucinated response. A grounded answer from your own knowledge base. We build RAG systems that connect to your existing document infrastructure, handle permissions and access control, and improve continuously as your knowledge base grows.
How We Work
We start by auditing your knowledge base: where documents live, how they are organized, how frequently they change, and what questions your team needs answered most often. That audit shapes the ingestion pipeline. We connect to your document sources, process content into optimally sized chunks, generate embeddings, and store them in a vector database. The retrieval pipeline is tuned for your specific domain vocabulary and question patterns.
The generation layer synthesizes answers grounded strictly in retrieved content with source citations on every response. We configure guardrails that decline to answer when confidence is low rather than generating plausible but incorrect responses. Deployment options include web interface, Slack bot, Teams integration, API endpoint, or embedded widget in your existing applications. We monitor retrieval accuracy, track which questions go unanswered, and continuously improve the system as your knowledge base evolves.