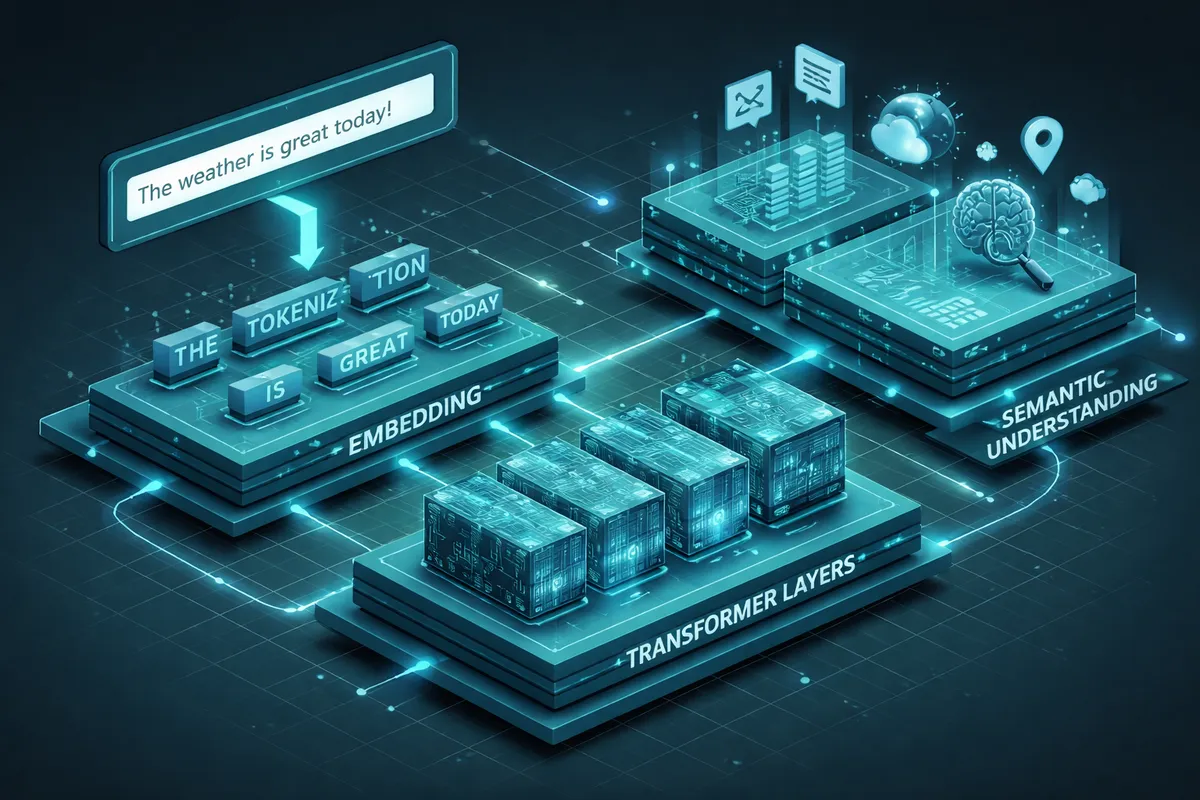
How We Build NLP Solutions for Streeterville
Our process begins with understanding your text data and your extraction needs. We interview your team to understand what information they currently extract manually from text, what errors occur in that process, and what decisions depend on that extracted information. For a hospital, we review clinical notes to understand the medical terminology, the way diagnoses and procedures are documented, and the relationships between documented information. For a law firm, we review contracts to understand what terms are important, how they are typically worded, and where variations signal risk. For a hotel, we review guest feedback to understand what drives satisfaction and dissatisfaction.
We then select the right NLP technology for your use case. Some text extraction requires simple rule-based patterns. Other extraction requires machine learning models trained on your specific domain. We evaluate your text data and recommend the approach that delivers accuracy and maintainability specific to your situation.
Implementation includes three components:
Text preprocessing and preparation covers automated ingestion from source systems with appropriate compliance controls: HIPAA-compliant access for healthcare notes, secure handling for legal documents, and review platform integration for hospitality feedback. Text is cleaned and structured for reliable model processing.
Extraction model training uses labeled samples of your specific text data. For medical documentation, labels cover diagnoses, procedures, medications, and outcomes. For contracts, labels cover liability clauses, insurance provisions, and termination rights. For guest feedback, labels capture sentiment and reason phrases. Trained models then apply these patterns to all incoming text automatically.
Integration and reporting delivers extraction results into your existing workflow systems. For a hospital, extracted information pre-populates the billing system for coder verification. For a law firm, key terms appear in a contract analysis dashboard. For a hotel, sentiment trends and specific quotes feed a guest feedback dashboard.
Industries We Serve in Streeterville
Healthcare systems and hospitals near Northwestern Memorial Hospital use NLP to extract diagnoses, procedures, and clinical decisions from narrative clinical notes. The system learns medical terminology and the way physicians document conditions so it can identify missed documentation or patterns that suggest quality issues. Hospital coders review system-extracted information rather than manually reading notes, improving speed and accuracy.
Medical practices and specialty clinics operate with smaller coding and documentation teams that cannot employ specialists for every medical specialty. NLP systems extract clinical information from notes so that general coders can verify coding decisions without requiring deep medical knowledge. This improves documentation quality and reduces coding errors.
Law firms and professional services companies in Streeterville office buildings use NLP to analyze contracts, identify key terms and obligations, flag non-standard language, and summarize contract obligations. Associates spend less time reading and summarizing and more time analyzing and advising clients on contract implications.
Hotels and hospitality operations along Michigan Avenue use NLP to analyze guest reviews and feedback for sentiment, extract specific complaints or compliments, and identify emerging service quality issues. A dashboard shows guest satisfaction trends and surfaces specific feedback that requires management response.
Real estate and property management companies use NLP to analyze tenant communications, maintenance requests, and lease documents to identify patterns, surface recurring issues, and extract terms that require monitoring or renewal action.
Corporate offices and professional services use NLP to analyze internal documents, customer communications, and business correspondence to extract key information, identify risks or opportunities, and support business intelligence and decision-making.
What to Expect Working With Us
1. Text data audit and use case definition: We review your text data for volume, format, and content, then interview your team to understand what is currently extracted manually and what decisions depend on that extraction. For a hospital, this might focus first on diagnoses and procedures. This phase takes 2 to 3 weeks.
2. Training data preparation and model development: We label 200 to 500 text samples per extraction task in collaboration with your team members who understand the content. Model accuracy depends directly on training data quality. This phase takes 3 to 6 weeks depending on team capacity.
3. Model validation and refinement: We test models on new text they have not seen before, evaluate accuracy, and refine training until healthcare and legal use cases meet a 90-plus percent accuracy threshold. This phase takes 2 to 4 weeks.
4. Integration and deployment: We wire extraction results into your existing workflow systems and train your team to use them. Ongoing monitoring includes monthly accuracy reviews and model refinement as your document types evolve.