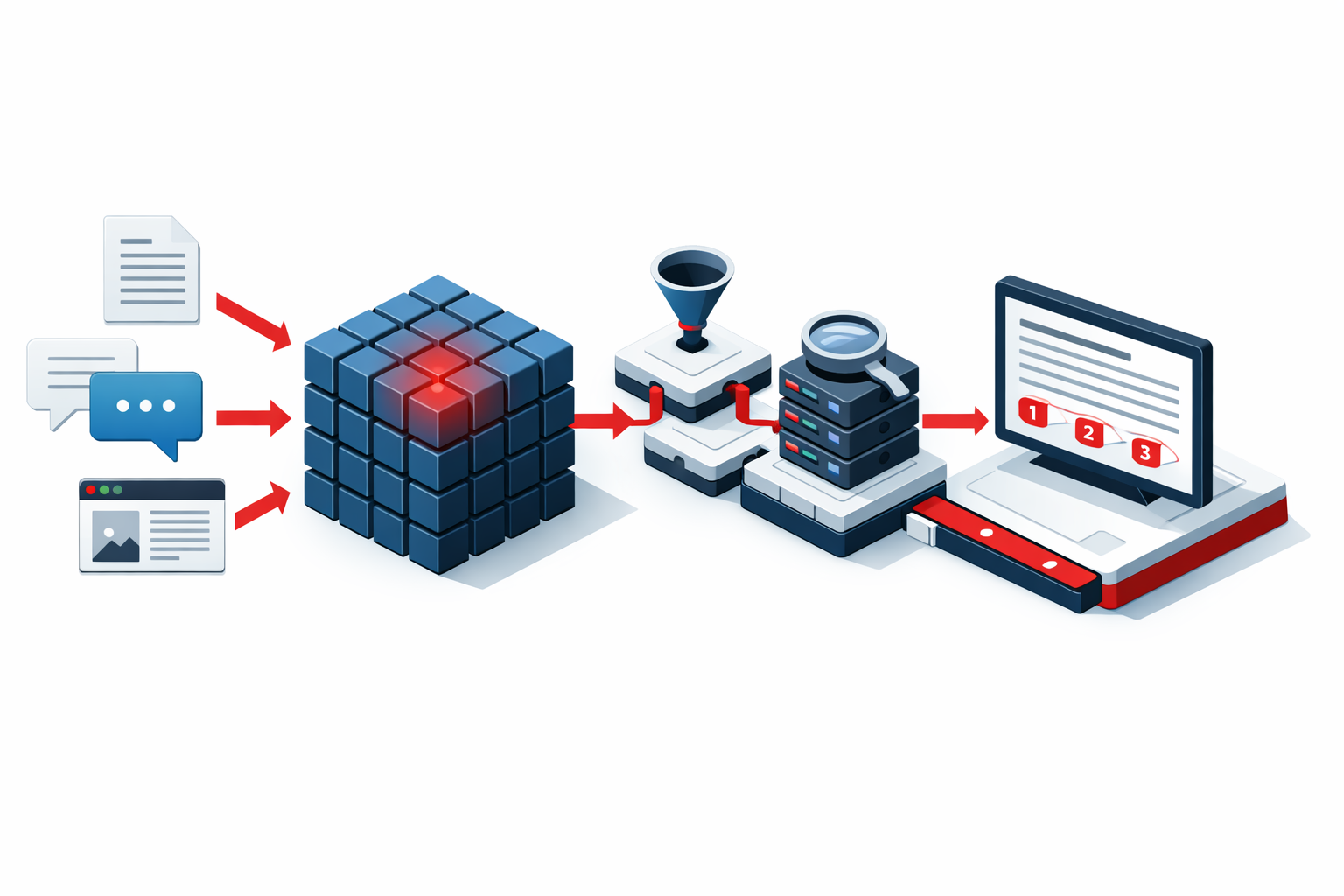
How We Build RAG Systems for South Loop
RAG development begins with a document and data inventory. We catalog the document types in your South Loop organization's knowledge base: contracts, research reports, policies, procedures, exhibit materials, legal precedents, client files, and any other structured or unstructured content that the RAG system should be able to retrieve and answer from. The inventory includes volume, format, language, and the access controls that determine which users should be able to retrieve which documents.
From the inventory, we design the retrieval architecture. Document chunking strategy, which determines how documents are split into retrievable segments, significantly affects retrieval accuracy and must be calibrated to your specific document types. A South Loop law firm's contracts require different chunking than a Museum Campus institution's exhibit descriptions. Embedding model selection determines how documents are indexed for semantic search. Retrieval configuration determines how many document chunks are retrieved per query and how retrieved context is assembled for the AI.
Integration with your South Loop organization's document systems, whether that is SharePoint, Google Drive, Dropbox, a proprietary document management system, or a database, connects the RAG system to the live document repository rather than requiring a separate static knowledge base that becomes outdated as documents are added and updated.
The AI layer generates the final response using the retrieved content as grounding, with instructions that constrain the response to what was found in the documents rather than allowing the AI to supplement retrieved content with training knowledge that may be inaccurate for your specific context.
Industries We Serve in South Loop
Financial and investment services on Michigan Avenue build RAG systems for client-facing and internal AI applications that answer questions from portfolio documentation, regulatory guidance, client agreements, and proprietary research. A South Loop investment advisory firm with a RAG system gives advisors the ability to ask natural language questions about client portfolios and get accurate answers drawn from actual portfolio documentation rather than relying on memory or manual document search.
Legal and professional services near Printers Row build RAG systems for case research assistance, contract review support, and the knowledge management applications that allow attorneys to query the firm's matter history and precedent library through natural language. A South Loop law firm's RAG system becomes more valuable over time as the matter library grows, giving newer attorneys access to the firm's institutional knowledge that previously existed only in senior attorney memory.
Museum Campus cultural institutions build RAG systems for visitor-facing exhibit companions and internal curatorial knowledge management. A visitor AI companion that answers questions about specific exhibits, artifacts, and scientific concepts draws from the institution's authoritative curatorial documentation rather than from the general training knowledge that would produce inaccurate or oversimplified answers about specific collection items.
Property management firms on State Street and Roosevelt Road build RAG systems for tenant service AI that answers questions from lease agreements, building rules and policies, and maintenance documentation. A South Loop residential tower's tenant service RAG system answers lease and policy questions accurately from the actual documents rather than from generic rental law knowledge that may not reflect the specific lease terms.
Healthcare practices on Roosevelt Road build RAG systems for clinical documentation assistance, administrative Q&A, and the patient communication support that requires answers grounded in the practice's specific protocols and policies rather than generic medical information that may not reflect the practice's clinical approach.
Columbia College-adjacent educational organizations build RAG systems for curriculum access, policy Q&A, and the student support applications that answer questions from institutional documentation rather than from generic educational AI responses.
What to Expect Working With Us
1. Document inventory and architecture design. We inventory your South Loop organization's document corpus, design the chunking and retrieval architecture appropriate for your document types and query patterns, and specify the access control model that ensures users only retrieve documents they are authorized to access.
2. Document processing and indexing. We process your existing document library through the chunking and embedding pipeline, build the vector index that enables semantic search, and configure the retrieval parameters that produce accurate retrieval for the query types your South Loop users will submit.
3. AI response layer and interface development. We build the AI response layer that converts retrieved content into coherent, cited answers, and the user interface through which your South Loop organization's users interact with the system. The interface may be a chat window, a search interface, or an integration into an existing tool your team uses.
4. Testing, accuracy validation, and deployment. We test the RAG system against a set of representative questions your South Loop team has provided, validate retrieval accuracy and response quality, and deploy to production with monitoring that tracks query volume, retrieval quality, and user satisfaction signals.