How We Build RAG Systems for Pilsen Businesses
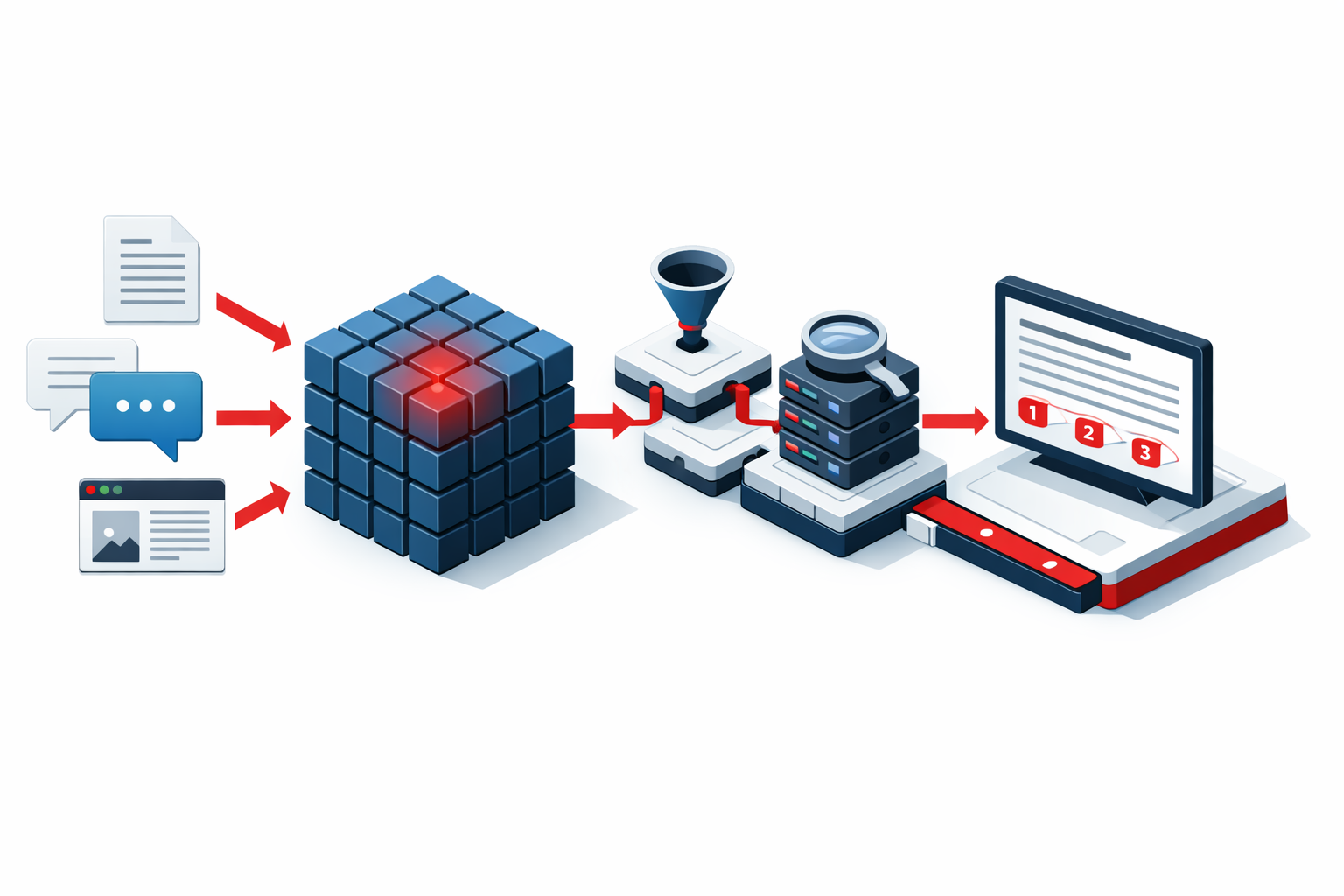
RAG system development begins with a document and knowledge audit. We understand what you want the system to answer, what documents it needs to draw from, and how current and authoritative those documents are. A RAG system is only as good as the knowledge base it draws from. Documents that are outdated, inconsistent, or poorly structured produce unreliable answers. We help organizations assess their document libraries and identify the cleaning and organization work needed before building the RAG system on top of them.
Document processing and embedding is the technical core of RAG development. We process your documents: splitting them into appropriately sized chunks, generating vector embeddings that capture semantic meaning, and storing those embeddings in a vector database that can be searched efficiently when a question is asked. For bilingual documents, we process both language versions and configure the retrieval to find relevant content regardless of which language the question is asked in.
Retrieval design determines how the system finds relevant information when a question is asked. The retrieval strategy affects answer accuracy more than any other component: a system that retrieves the wrong documents cannot produce a correct answer regardless of how capable the language model is. We design retrieval strategies that account for your specific document structure, the types of questions users will ask, and the coverage needed to answer questions accurately when relevant information is spread across multiple documents.
Language model integration connects the retrieved documents to the language model that generates the final answer. We design the prompt structure that presents retrieved context to the model in a way that produces accurate, grounded answers rather than answers that blend retrieved information with model training data in ways that introduce inaccuracies.
Testing and evaluation is ongoing throughout the development process. We build evaluation sets from real questions your users are likely to ask and measure answer accuracy, groundedness, and relevance. We identify failure modes before the system goes live and address them in the retrieval and prompt design.
User interface design varies by use case. Internal knowledge tools typically use simple chat interfaces accessible to staff through a browser or integrated into existing tools. Customer-facing knowledge tools are embedded in websites or applications with appropriate context and conversation management.
Industries We Serve in Pilsen
Restaurants and food businesses on 18th Street use RAG systems for menu knowledge tools that answer allergen, ingredient, and preparation questions accurately for staff and customers. A system that gives servers instant, accurate answers to customer allergen questions from the actual recipe database eliminates the need to check with the kitchen for every inquiry and reduces the risk of allergen errors from imperfect recall.
Community organizations and nonprofits with multiple programs, complex eligibility requirements, and large document libraries use RAG systems to make program knowledge accessible to case managers, volunteers, and community members. For organizations serving multilingual communities, RAG systems that answer questions in Spanish from English source documentation significantly reduce the administrative burden of bilingual operations.
Legal and professional service offices serving the Pilsen community use RAG systems to make legal information, process documentation, and resource directories accessible to staff and to clients navigating complex systems. Immigration legal services, tenant rights organizations, and community legal aid offices serving Pilsen's community are natural applications for RAG systems that make legal information accessible without requiring a lawyer to answer every question.
Retail and product businesses use RAG systems to make product knowledge accessible to customer service staff and, where appropriate, directly to customers through online tools that answer detailed product questions from actual product documentation.
Healthcare and social service organizations serving Pilsen's community use RAG systems to make clinical protocols, eligibility criteria, referral information, and community resource directories accessible to frontline staff without requiring them to search large document libraries for every case.
What to Expect
Knowledge audit and system scope definition. We assess your document library, define the scope of what the RAG system will answer, and identify the document preparation work needed before development begins.
Document processing and infrastructure setup. We process your documents, set up the vector database, and implement the retrieval infrastructure. We test retrieval accuracy against your actual question patterns before proceeding to language model integration.
Language model integration and interface development. We integrate the retrieval system with the language model and build the user interface appropriate for your specific use case.
Testing and refinement. We evaluate the system against real questions, identify and address failure modes, and validate performance before launch.
Maintenance and knowledge base updates. We provide guidance on updating the knowledge base as documents change and offer ongoing maintenance for organizations whose document libraries evolve frequently.