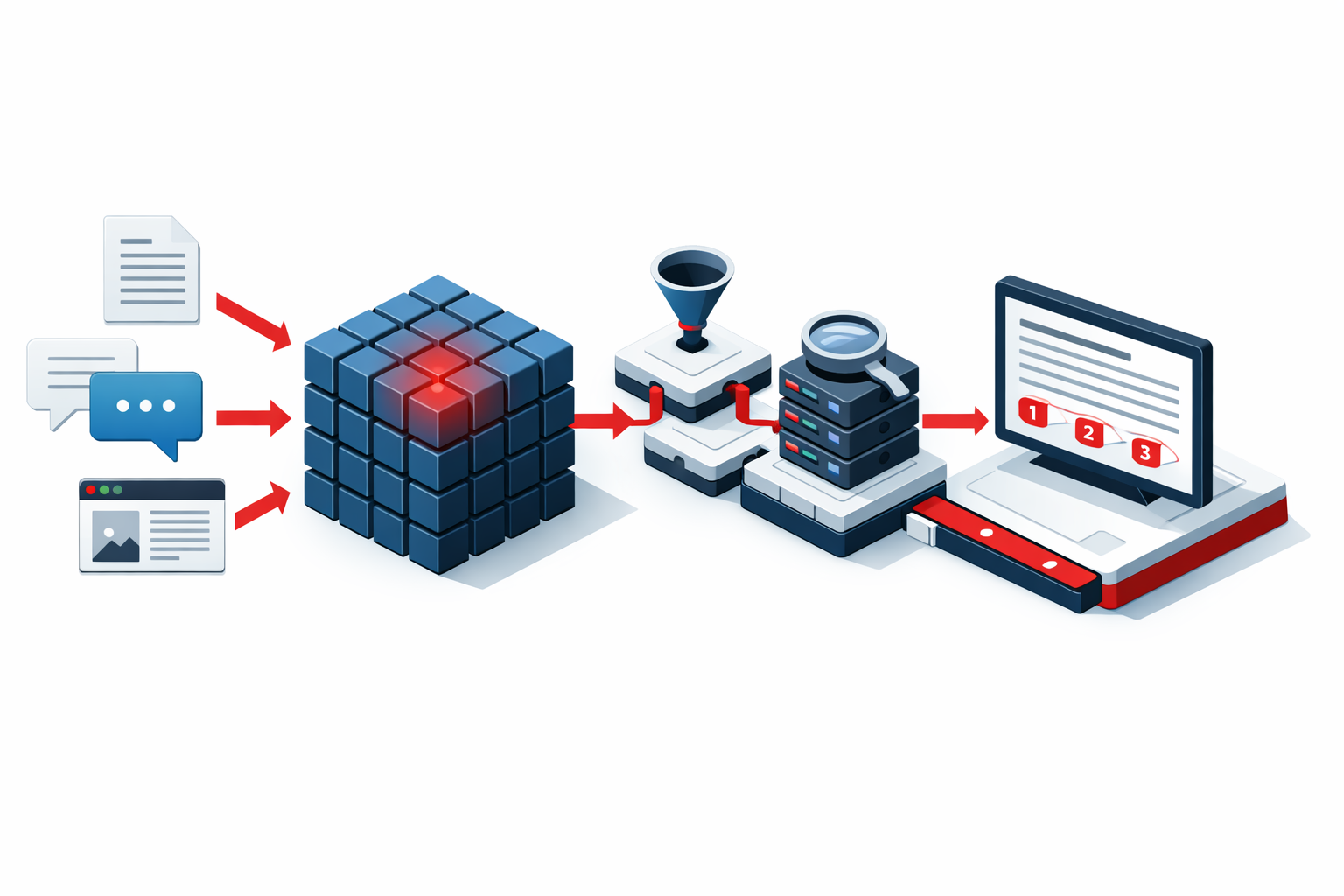
How We Build RAG Systems for Hyde Park
Every RAG engagement begins with a knowledge audit. We document what exists, where it lives, who needs access, and what questions your team asks most frequently. For Hyde Park's academic and research clients, this audit includes data governance mapping: we identify which documents carry IRB restrictions, which carry HIPAA obligations, which are restricted by grant data management agreements, and which are freely accessible to all staff. This governance mapping drives the permission architecture of the RAG system.
Document source connection for Hyde Park organizations typically involves the full range of institutional document platforms: SharePoint and OneDrive for UChicago-affiliated organizations that use Microsoft 365, Google Drive for nonprofits and smaller organizations, Confluence for research teams using Atlassian tools, institutional repository systems for published research, email archives for organizations where significant institutional knowledge lives in email, and specialized databases for healthcare and legal organizations.
The chunking and embedding strategy for Hyde Park's academic content requires specific calibration. Research documents are structured differently from operational procedures, which are structured differently from grant narratives, which are structured differently from clinical protocols. We configure chunking and embedding parameters for the specific document types in each organization's corpus, which produces meaningfully better retrieval accuracy than generic settings applied uniformly across all document types.
Permission-aware retrieval is non-negotiable for Hyde Park's regulated organizations. A researcher should only receive answers from documents they are authorized to see. A clinical staff member should only receive answers from documents appropriate to their role. We implement permission controls that integrate with Active Directory, Google Workspace identity management, and institutional SSO systems so that access to retrieved content mirrors the access controls already in place on the source documents.
Industries We Serve in Hyde Park
Academic research centers and UChicago research organizations use RAG systems to make their accumulated research documentation, IRB protocols, methodology records, and institutional grant history searchable in seconds. Research staff find precedents, methodologies, and prior work without the hours of manual searching that currently consume time that should go to research.
UChicago Medicine-affiliated practices and healthcare organizations use RAG systems to provide instant access to clinical protocols, billing and insurance guidelines, referral procedures, and administrative policies with citation links that allow practitioners to verify the source immediately.
Polsky Center ventures and academic startups use RAG systems to make their product documentation, customer history, support knowledge bases, and competitive intelligence searchable for sales, support, and product teams who need answers faster than manual search allows.
Nonprofits and community organizations throughout Hyde Park use RAG systems to preserve institutional memory across staff transitions, surface past grant proposals for new funding applications, and give program staff instant access to policy documentation and program guidelines.
Law firms and professional services organizations serving the Hyde Park academic and hospital community use RAG systems to search engagement histories, research precedents, and client documentation with role-based access controls that protect client confidentiality.
What to Expect Working With Us
1. Knowledge audit. We document your document ecosystem: what exists, where it lives, what access controls govern it, what questions your team asks most frequently, and what governance requirements shape how it can be accessed through a RAG system. The audit produces the design blueprint for every subsequent decision.
2. System design and document ingestion. We connect to your document sources, process content into appropriately sized chunks calibrated to your document types, generate embeddings, and store them in a vector database tuned for your domain vocabulary. Permission-aware retrieval architecture integrates with your identity management systems.
3. Interface deployment. The system deploys as a web interface, a Slack or Teams integration, an API endpoint for embedding in existing tools, or a combination of interfaces appropriate to how your team works. Every response includes source citations. Guardrails decline to answer when confidence is low rather than generating plausible responses from insufficient evidence.
4. Ongoing optimization. We monitor retrieval accuracy, track questions the system cannot answer that represent knowledge gaps to address, and improve the system as your knowledge base evolves. Automated pipelines re-index updated documents within hours of changes. Monthly reviews assess retrieval quality based on real usage patterns.