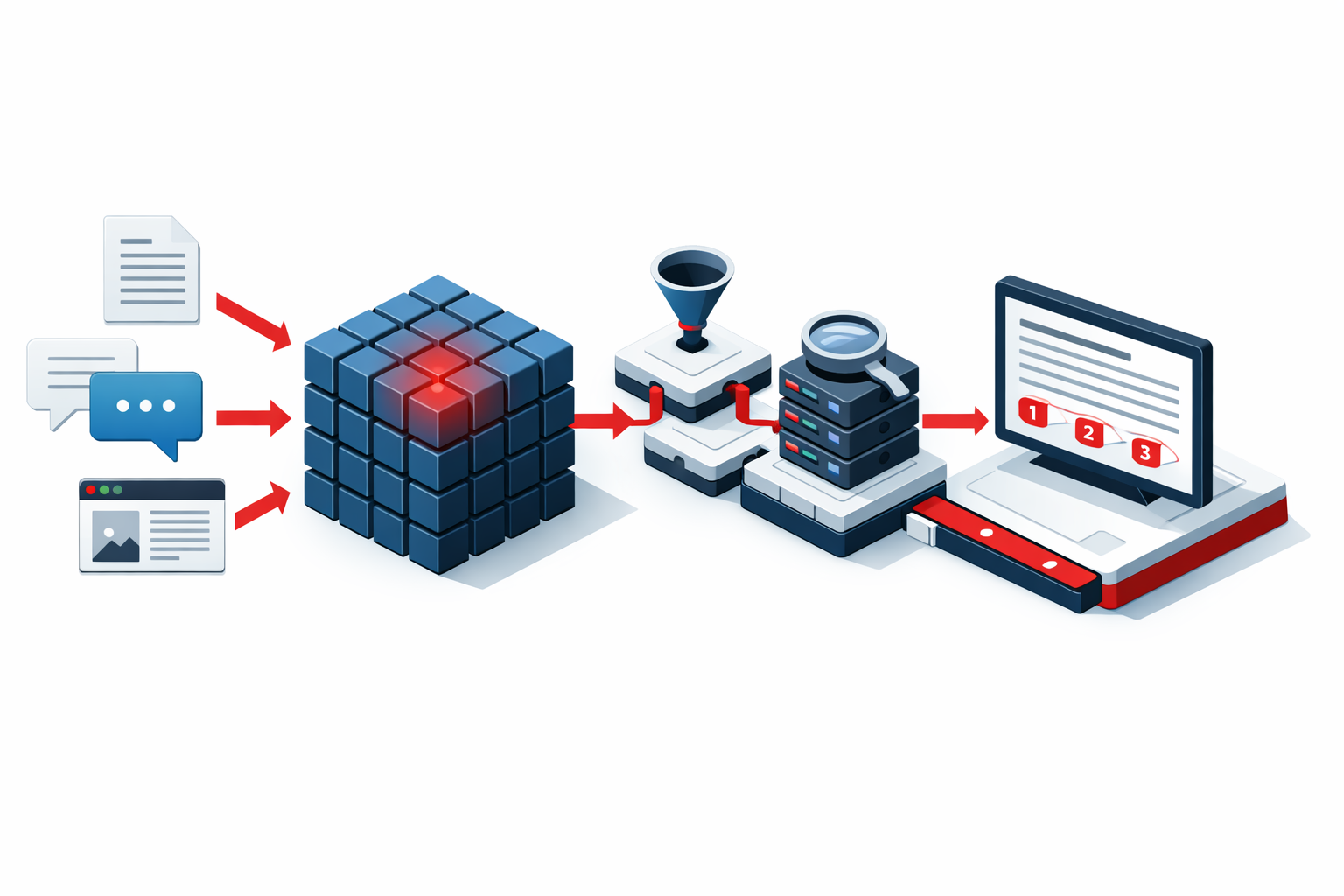
How We Build RAG Systems for Evanston
We start with a document library assessment. We catalog the documents your organization wants to make accessible through the RAG system: the types, the volume, the formats, the quality, and the access controls that govern them. For a law firm, that might include completed matter files, precedent documents, research memoranda, and form libraries. For a consulting firm, it might include past engagement deliverables, internal research reports, and proprietary methodology documents.
We design the document processing pipeline. Converting your existing documents into a format that RAG systems can search efficiently requires preprocessing work: text extraction from PDFs and Word files, handling of scanned documents, metadata tagging that enables filtered retrieval, and chunking strategies that preserve semantic coherence while enabling precise retrieval. The preprocessing design affects the quality of retrieval significantly.
We build and configure the vector database that stores the processed documents. The vector database is the retrieval engine of the RAG system. It stores document chunks as mathematical representations that allow semantic similarity search: when a staff member asks a question, the system finds the document chunks that are most semantically relevant to that question, not just keyword-matched. The database design and the retrieval algorithms determine how accurately the system surfaces the most relevant documents for each query.
We integrate the retrieval system with the AI layer. The AI receives the retrieved document chunks along with the user's question and synthesizes a response that is grounded in those specific documents. We design the prompting that governs this synthesis to maintain accuracy, include citations to the source documents, and flag uncertainty when the retrieved documents do not contain a clear answer.
We implement access controls that ensure staff can only retrieve documents they are authorized to access. A junior associate's RAG queries should not surface documents from matters where they are not engaged. The access control layer in the RAG system maps to your organization's existing document access policies.
Industries We Serve in Evanston
Law firms and legal practices on Sherman Avenue and throughout Evanston use RAG systems to make completed matter files searchable, build a precedent retrieval system that surfaces relevant prior work for current matters, create a form and template library that returns the most appropriate starting point for each document type, and enable research assistants to query the firm's internal knowledge base alongside external legal databases.
Consulting and advisory firms near Central Street use RAG systems to make past engagement deliverables accessible for current project teams, build a methodology knowledge base that surfaces the firm's approaches and frameworks for specific problem types, and create a lessons-learned system that helps teams avoid repeating past mistakes and build on past successes.
Healthcare and research organizations near Northwestern University use RAG systems to build clinical reference systems that retrieve relevant guidelines and protocols for specific patient presentations, create literature synthesis tools that connect to curated research libraries, and build organizational knowledge systems that preserve and surface the expertise of senior clinical and research staff.
Wealth management and financial advisory firms near Grosse Point Lighthouse use RAG systems to make investment research archives searchable, build client history retrieval systems that surface relevant past interactions when preparing for client meetings, and create regulatory reference systems that retrieve relevant compliance guidance for specific situations.
Academic and research-adjacent organizations near Northwestern build RAG systems for literature management and synthesis, grant database retrieval, institutional knowledge preservation, and interdisciplinary research support that connects expertise across departmental boundaries.
Professional training and continuing education organizations near the Evanston Public Library build RAG systems to make curriculum archives accessible for new content development, create subject matter expert knowledge bases that preserve the expertise of instructors who have left the organization, and build adaptive content systems that retrieve appropriate materials for specific learner profiles.
What to Expect Working With Us
1. Document library assessment and architecture design. We assess your document library and design the RAG system architecture: document processing pipeline, vector database configuration, retrieval strategy, AI integration, and access control design. We deliver an architecture specification for your review before development begins. This phase takes two to three weeks.
2. Document processing and database build. We process your document library through the preprocessing pipeline, build the vector database, and validate retrieval quality against a test set of queries. We test retrieval accuracy and adjust chunking strategies and retrieval parameters until the system surfaces the right documents consistently.
3. AI integration and query interface. We integrate the retrieval system with the AI layer, configure the synthesis prompting, and build or configure the query interface your team will use. We test the full system against realistic queries from your team members and refine based on their feedback.
4. Deployment, access control configuration, and training. We deploy the production system with appropriate access controls, train your team on effective query strategies, and document the system's capabilities and limitations. We monitor query quality for the first 30 days and address any retrieval or synthesis quality issues identified in production use.